Verilog in seconds.
No testbench needed.
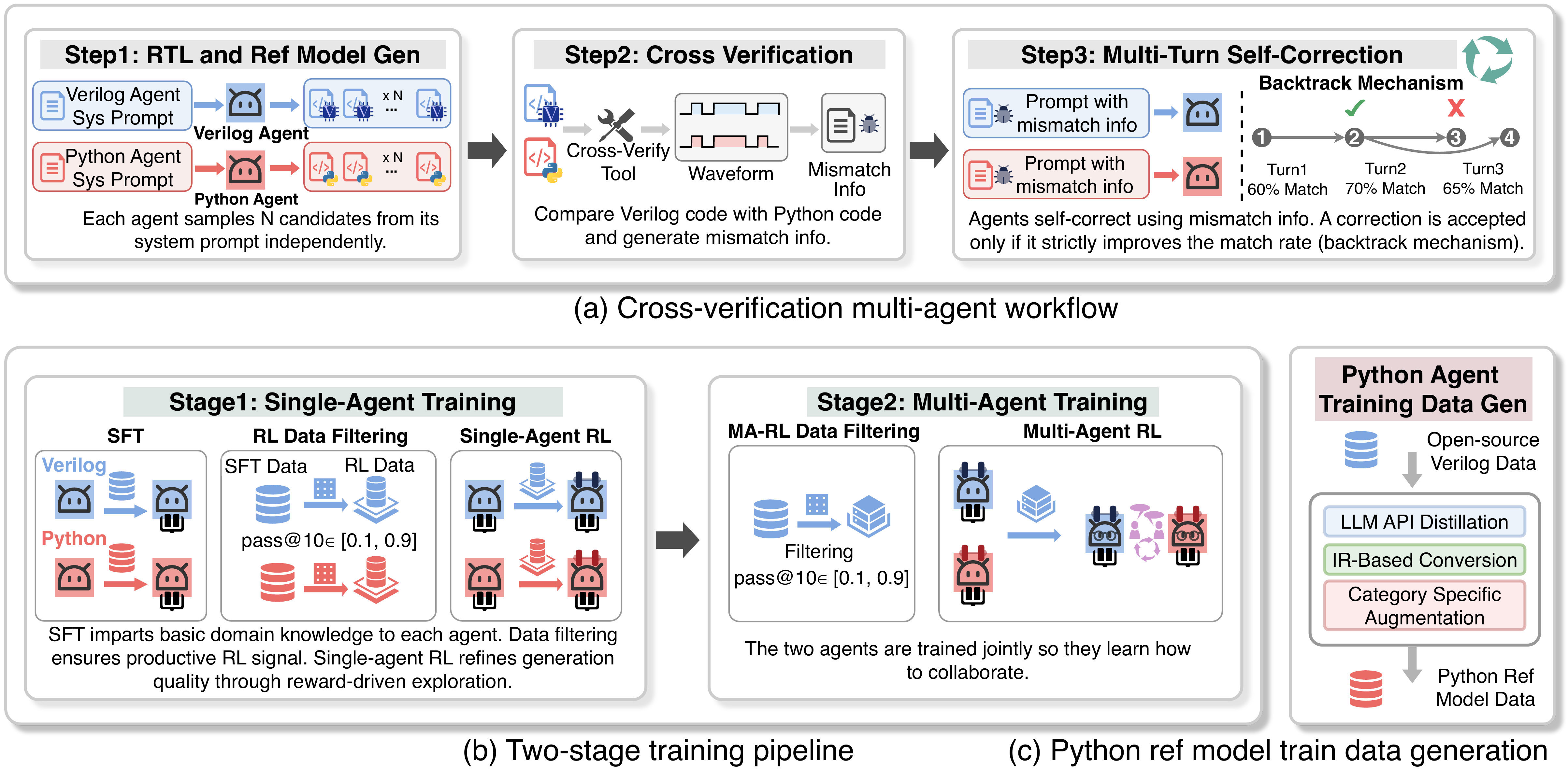
ChipMATE is a self-trained multi-agent framework. A Verilog agent and a Python reference-model agent cross-verify each other on random stimuli — no golden oracle. Try it directly below.
Two agents. Cross-verified.
Most RTL generators rely on a golden testbench — a curated oracle that says "this is correct". ChipMATE has neither at train nor inference time. Instead, two agents independently propose implementations of the same spec, then probe each other with random stimuli. Agreement is the only signal.
Verilog agent
Proposes a synthesizable top_module implementation. Optimized
during RL with reward shaped on cross-agreement, not on test-pass rate. Sees
only the natural-language spec + port skeleton — no reference solutions.
Python ref-model agent
Independently writes a Python function that emulates the same spec — cycle- accurate for sequential logic. This is the oracle proxy: any mismatch with the Verilog DUT under random inputs is a candidate bug in either agent.
Cross-verify harness
Compiles the Verilog under iverilog, drives random port stimuli,
compares cycle-by-cycle against the Python model. Reports a match rate ∈ [0, 1]
and a structured diagnostic when they disagree.
Feedback loop
Disagreement traces are fed back as natural-language diagnostics for the next
turn. After ≤ 5 rounds, the loop either reaches match_rate = 1.0
or surfaces the best candidate. No oracle, no curated testset.
Punching 200× above its weight
ChipMATE's two open-source checkpoints (4B and 9B base) beat DeepSeek V4 — a 1.6-trillion-parameter MoE — on VerilogEval V2 pass@1. Below: per-model accuracy on the public benchmark.
| Model | Type | Params | VerilogEval V2 pass@1 |
|---|---|---|---|
| GPT-4o | API | ~undisclosed | 53.4% |
| Claude 3.5 Sonnet | API | ~undisclosed | 59.7% |
| DeepSeek V4 | API · open | 1.6T (MoE) | 71.2% |
| ChipMATE-Agents-4B | open · self-hostable | 4B | 75.0% |
| ChipMATE-Agents-9B | open · self-hostable | 9B | 80.1% |